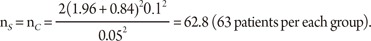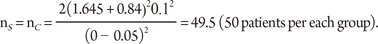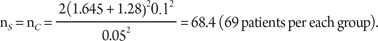In this section, we explain the methods for calculating sample sizes in clinical researches according to various purposes of study, such as equality, non-inferiority, superiority, and equivalence, which appeared in the article titled, "Effects of Korean red ginseng on cardiovascular risks in subjects with metabolic syndrome: a double-blind randomized controlled study", published in July 2012 by Park et al.1)
Determination of a Sample Size
In most clinical trials, the primary study objective is usually related to the evaluation of the effectiveness and safety of a drug product. For example, it may be of interest to show that the study drug is effective and safe as compared to a placebo. In some cases, it may be of interest to show that the study drug is as effective as, superior to, or equivalent to an active control agent or a standard therapy.
Thus, hypotheses regarding medical or scientific questions of the study drug are usually formulated based on the primary study objectives. The hypotheses are then evaluated using appropriate statistical tests under a valid study design.2)
1. Hypotheses
A typical approach for demonstration of the efficacy and safety of a study drug under investigation is to test one of the following hypotheses (Here, we assume that the primary study object is the comparing means which is obtained from a two-sample parallel design).
1) Test for equality
where ┬ĄS and ┬ĄC are the mean responses for the study and control drugs, respectively.
2) Test for non-inferiority
where ┬ĄC and ┬ĄS are the means for the control (standard) and study drugs, respectively, and ╬┤ is a difference of clinical importance which is usually called the "non-inferiority margin."
2. Formulae
For all cases, we further assume that both groups have equal numbers of patients, i.e., nS = nC, the true mean difference between the two groups is ╬Ą = ┬ĄS - ┬ĄC (>0), and Žā2 is a pooled estimate of the variance in both groups.
1) Test for equality
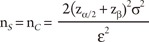
where z╬▒/2 and z╬▓ are the upper (╬▒/2)th quantile and the upper (╬▓)th quantile of the standard normal distribution, respectively.
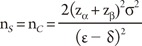

3. Examples
Consider the situation that a pharmaceutical company is interested in conducting a clinical trial to compare two cholesterol lowering agents for treatment of patients with coronary heart disease through a parallel design. The primary efficacy parameter is the low density lipoprotein (LDL). In what follows, we will consider the situations where the intended trial is for 1) testing equality of mean responses in LDL, 2) testing non-inferiority or superiority of the study drug as compared to the active control agent, and 3) testing for therapeutic equivalence. All sample size calculations are performed to achieve 80% power (i.e., ╬▓ = 0.20) at 5% level of significance (i.e., ╬▒ = 0.05).
1) Test for equality
From the previous studies or a pilot study, we obtain the mean difference between two drugs as 5% in percent change of LDL, which can also be considered as the clinically meaningful difference, and the standard deviation is 10%. Then